mirror of
https://github.com/advplyr/audiobookshelf.git
synced 2026-03-02 22:46:55 -05:00
Some books not matching #11
Labels
No labels
authentication
awaiting release
backlog
bug
chapter editor
config-issue
ebooks
encoding/embedding
enhancement
help wanted
listening sessions & progress
planned
possible plugin
progress sync
sorting/filtering/searching
unable to reproduce
upload
users & permissions
waiting
No milestone
No project
No assignees
1 participant
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference
starred/audiobookshelf-advplyr#11
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Originally created by @Merijeek on GitHub (Aug 28, 2021).
So...I've got some books not matching. I'm guessing the title is off by a tiny bit.
What is the matching source? It would be good to know so that I can look them up manually and rename appropriately so that matching works correctly.
@advplyr commented on GitHub (Aug 28, 2021):
The BookFinder is weak right now. There are just not many good options.
First it checks Open Library
if it doesn't find a very close match, it also searches LibGen
I am looking into setting up a separate book database.
@Merijeek commented on GitHub (Aug 29, 2021):
Interesting - some of the books I've got aren't in there. For example, Robert Bevan has a good 14 or 15 books, but only his first one (Critical Failures) is in OL, and near as I can tell, even that one isn't in LG.
@advplyr commented on GitHub (Aug 30, 2021):
Google Books might be the most expansive, but it isn't free.
Good Reads was another big one, but they shut that down for public use.
There is a need for a clean, open book database and I think it is worth pursuing once this project is stable.
@Budlyte commented on GitHub (Sep 16, 2021):
While the matching is pretty decent, and I love the name parsing the Subtitle since it fits my naming scheme, is there a naming scheme that lends to parsing the Volume # ?
@advplyr commented on GitHub (Sep 17, 2021):
There is not, but it seems logical to add that. What did you have in mind?
@Budlyte commented on GitHub (Sep 17, 2021):
My goodness, either we're on opposite sides of the planet or you don't sleep. If you're missing sleep for this, please don't let us bugging you keep you up.
It looks like libgen contains the series number, though it's randomly placed in the book title or the series name... but a quick regex match for digits in either when matching the book up should be able to pull it out. Though this might break matching titles or series that legitimately contain numbers in their name. Hmmmm. Well the number seems to always be at the beginning or end of either, and I'd say a number in the series name should be taken over the title as those are less common to iterate.
Here's what I'm guessing Libgen kicks out from its API, I stumbled upon a page that gave this and seemed to contain a shitload of links to viruses.
@book{book:{6225211},
title = {Armageddon},
author = {Alanson, Craig},
year = {2019},
series = {Expeditionary Force 8},
url = {libgen.li/file.php?md5=0dde1ba14f89f901e24e36cb72d5e792}}
So, after removing the curlies, a regex match could look like:
Check the series first
It looks like you're already trimming the whitespace from the remainders.
Now, if we want to get into actually parsing the Volume # from the filename.... I understand that my naming scheme is probably unique but others probably use something similar. The parser could look to match the following, again assuming you're using regular expressions:
Getting started in someone else's code is difficult, but if you want to point me towards where this thing is written, I can take a look.
@advplyr commented on GitHub (Sep 18, 2021):
Not a bother at all, the opposite actually, these suggestions and bug catches are taking this project to the next level.
This is added in
v1.1.13, I updated the readme with some details.I didn't include
v \d+because I think it would have too many false positives.The regex that I went with is
/(-? ?)\b((?:Book|Vol.?|Volume) (\d{1,3}))\b( ?-?)/iTested in regex101
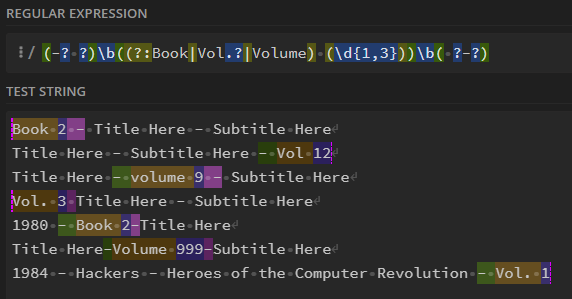
Where group 3 (purple) is what gets stored in the Volume Number. The other groups are there to help with removing it from the title.
It is here in the code.
@advplyr commented on GitHub (Sep 18, 2021):
I'm going to keep this issue open because matching with LibGen and OpenLib is still not improved. Volume number and series aren't parsed during matching, it needs a full overhaul.
@Budlyte commented on GitHub (Sep 18, 2021):
lol I'm sitting here writing expressions in crayon, meanwhile you're elegantly writing with a quill.
Thanks a ton for the update, it'll help a lot to fill in that blank area. I assume it's only filling in the Volume # if it's empty. Out and about today, no chance to really test anything yet.
@Budlyte commented on GitHub (Sep 18, 2021):
If you're going to overhaul anyway, getting a Google books API key is easy, if you add support for it then it wouldn't be unreasonable to require people get their own keys. LibGen kind of worries me after that wack page I landed on with nonstop popups from it.
@Budlyte commented on GitHub (Sep 18, 2021):
Alright, home now and can scan. It looks like that code only runs on newly created files, which makes sense because the way it is now would null out any manually set volumenumber. I think this is fine, because as people pull in their libraries, then figure out what naming scheme can do what, make those updates, then they just hit Reset and import again.
Great work! Now I think it's a bummer I didn't open a req for this because it would make a nice Closed piece.