mirror of
https://github.com/photoprism/photoprism.git
synced 2026-03-02 22:57:18 -05:00
Indexer: Stand alone indexer #822
Labels
No labels
ai
android
api
auth
awesome
bug
bug
ci
cli
config
database
declined
deprecated
docker
docs 📚
documents
duplicate
easy
enhancement
enhancement
enhancement
epic
faces
feedback wanted
frontend
hacktoberfest
help wanted
idea
in-progress
incomplete
index
invalid
ios
labels
live
live
low-priority
macos
member-feature
metadata
mobile
nas
needs-analysis
no-coding-required
no-coding-required
observability
performance
places
please-test
plus-feature
priority
pro-feature
question
raspberry-pi
raw
released
released
released
research
resolved
security
sharing
tested
tests
third-party-issue
thumbnails
upgrade
upstream-issue
ux
vector
video
waiting
won't fix
won't fix
No milestone
No project
No assignees
1 participant
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference
starred/photoprism#822
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Originally created by @darrepac on GitHub (Feb 26, 2021).
Hi,
I am running Photoprism on a Pi. It is really slow to index....in fact the main bottleneck is the index task. Then serving files through web, Pi is good enough in my opinion.
Particularly for the first index, or when you import ton of files, it could be useful to have a running executable (simple one) that creates all the needed files (thumbnails and others) that we can temporary run from a more powerful machine.
Thumbnails and others could then move to the right places (or can be in place)
@lastzero commented on GitHub (Feb 26, 2021):
You can actually run photoprism in a terminal - only copying files from one device to another is manual work if you don't have a shared filesystem.
@alexislefebvre commented on GitHub (Feb 26, 2021):
In theory, it should be possible to index files from another computer if the files are mounted to the same path in the container and if the same database is used.
@darrepac commented on GitHub (Feb 26, 2021):
Ok but it would mean to install docker and the full photoprism... quite heavy
(Personnaly I was not able to understand how to run it on windows, but was the first I even install docker on windows)
@lastzero commented on GitHub (Feb 26, 2021):
Well, indexing and transcoding media files requires more than a small script. Installing all dependencies manually is even more work and needs the same amount of storage.
@lastzero commented on GitHub (Mar 1, 2021):
Is this really a feature request? What specifically should be developed and how?
@darrepac commented on GitHub (Mar 1, 2021):
It is not a bug, it is a new feature for me, so that's why I put as feature request.
Then, I guess that now the goal is to see what others think about it: if it makes sense only to me, we can conclude that it doesn't make really sense for the community.
@darrepac commented on GitHub (Mar 8, 2021):
I have pictures and storage folders mounted on a NAS and so shared accross my network.
If I install Photoprism on Ubuntu in computer A (i5 laptop so x86) and run a full scan.
Can I just run Photoprism on computer B (Raspberry, so Arm) by pointing to the same pictures and storage mount point?? or such files are platform dependant?
@cesarblancg commented on GitHub (Mar 19, 2021):
I have the same problem.
I have a rpi3b with syncthing and other self+hosted solutions and I'm searching a google photos alternative. I'm thinking about two instances of photoprism( one in my rpi and the other in my pc). The rpi will have the mariadb server and an instance of photoprism, and my pc will have the other photoprism with the originals folder under syncthing and connecting to the rpi mariadb server.
Could I connect the mobile app to the rpi photoprism and upload my media, and don't be indexed until I turn on the pc?
@lastzero commented on GitHub (Mar 19, 2021):
In theory yes, although that's a pretty complex setup and the Pi is perfectly capable of indexing a few files you just uploaded.
@sigaloid commented on GitHub (Dec 11, 2021):
I think a short tutorial on how to index with a stronger device would be helpful. I have a nice ryzen and 16GB of ram on my main PC but I want to eventually toss it on a pi and not think about it. The initial indexing is a serious burden for a lot of photos + facial recognition etc. Importing a few hundred when I sync shouldn't be too hard but I have thousands of photos to be imported on first run onto a 1GB ram Pi 2.
@alexislefebvre commented on GitHub (Dec 17, 2021):
I was able to launch a PhotoPrism container on another computer by following these steps.
Let's say that you have 2 computers, the server is the one that already run PhotoPrism, we'll use our local computer as a client to run PhotoPrism.
⚠️ Prerequisites:
docker-composestoragefolderOn your server:
photoprismcontainer (we don't want parallel accesses to the same database)docker-compose.yml, my local network is on the 192.168.1.X range so I use it to not open the port to Internet:photoprism-dbcontainer:docker-compose up --detach photoprism-dbOn your client:
We have to run PhotoPrism and it needs to access to the same paths than when it's running on the server.
docker-compose.ymlfile, keep only thephotoprismservicePHOTOPRISM_DATABASE_DSNvariable to use the database on the servervolumes::has to be updated and correspond to the paths that were mounted in the container:is kept as isYou should have something like this:
Start the
photoprismcontainer:docker-compose up --detach photoprism.Access to the PhotoPrism instance through the port you defined. You should see the same media than before.
I didn't do any benchmark, but the network may be the bottleneck with this setup.
@laterwet commented on GitHub (Jan 1, 2022):
The issue is not only for initial indexing, but also with complete rescan (re-indexing). Ideally, the indexer would support distributed computation, so we could register all available machines. This could be done with a simplified docker image that only creates thumbnails and runs classification on per-image task. The workers could communicate with the server via a simple API and queue service.
I have a photo library of 43k+ photos and it would take about 4 days for initial indexing. Using multiple PCs could reduce time significantly with a fast network.
I have good experience in distributed programming, I could possibly contribute to this kind of feature if the interest is high.
@lastzero commented on GitHub (Jan 2, 2022):
Our 2-core Intel Core i3 can index 100k+ files in less than a day. I would recommend buying better hardware instead of requiring much more complex (and expensive) software architecture to solve performance problems with small libraries. Development time is our scarcest resource.
@lastzero commented on GitHub (Jan 2, 2022):
By the way, you can already provide the index command with different subfolders as argument and run it on different computers. The only drawback is that the other computer has to access storage over the network, which can slow it down considerably. Overall, I don't think it's worth the effort for most users.
@gadolf66 commented on GitHub (Jan 19, 2022):
Hello, new to the forum, so, if you feel it's better to create a new thread, just let me know.
I want to work on a setup similar to others:
server 1 - Debian - has four usb drives to store the images, shared with the private network (Samba)
server 2 - Debian - Photoprism
I wonder if it's really necessary to install Photoprism on both machines, or just adding a volume on Photoprism server (server 2), pointing to the network share on server1.
Any thoughts?
Thanks in advance.
@lastzero commented on GitHub (Jan 19, 2022):
Local data storage is a big advantage / necessity when it comes to performance and data security:
If necessary, only originals should be stored on a network drive or a slow HDD. If you want to discuss this in more detail, it's best to start a thread (or join an existing one) in GitHub Discussions.
@gadolf66 commented on GitHub (Jan 19, 2022):
@lastzero Thanks for quick reply.
Yes, I was thinking only about originals. All other files would be local.
Now, the corrupted-files link you've provided says:
Just to make sure I correctly understood it (although it's quite obvious), by database files, you mean the database inner files, like the ones below, not the originals, right?
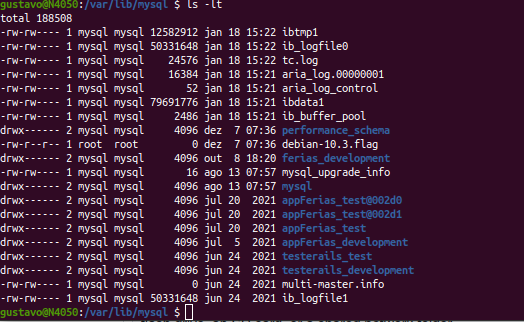
@mattodinaturas commented on GitHub (Feb 13, 2022):
well, I have a 2012 i5-3330 and it takes forever to index, for a folder of 50gb it takes a day or so. Definitely not your speed, if i were to rescan all 50k files i have now, it would take at least one week and a half of 24/7 work. I have now moved my storage folder and redone docker compose but now it started indexing all over and i don't have the time to wait. Is there anything i can do? i am running on docker hyper-v on windows server 2022. Thanks
@lastzero commented on GitHub (Feb 13, 2022):
Could be caused by file system virtualization. I know that accessing files on the host is extremely slow on macOS, so I wouldn't be surprised if Docker has similar issues on Windows.
With this background information, you can search Google for workarounds... others surely have similar performance problems. For example, there could be mount parameters to improve performance.
@mattodinaturas commented on GitHub (Feb 13, 2022):
thank you for your reply. I think you are right, since when I deployed nextcloud on a host folder it became really sluggish, the only way to fix it was to put every system folder of NC on a dedicated docker volume. Well, it's a bummer. I tried researching about this issue just now but most info is related to wsl rather than hyper-v. However if I use wsl2 is it right that I will not be able to access drivers other than C, as said in photo prism documentation or is there a workaround available? thank you
@lastzero commented on GitHub (Feb 13, 2022):
A user reported that mounting drives other than C: works with WSL2. However, we do not have details, and when we tested it months ago, it did not work. Maybe Microsoft has released an update in the meantime?
@djjudas21 commented on GitHub (Jul 14, 2022):
I'm interested in this, but from a different perspective. I am running PhotoPrism in a 3-node Kubernetes cluster, and I am interested in multiple replicas to benefit from that compute during indexing.
@centralhardware commented on GitHub (Jul 15, 2022):
you already can run index from CLI. something looks like
sudo docker run --entrypoint photoprism index. it's not exectly what you want but it's can be done write now.@dfldylan commented on GitHub (Nov 17, 2022):
It looks like this is the case, I am on windows10 with 21H2.
The new release recently updated support for nvidia-tookit, and as far as I know only wsl2 can call nvidia-tookit. so when I tried to switch from wsl1 to wsl2, I found that both D: and E: on the host are mounted properly into the container.
@graciousgrey commented on GitHub (Jul 11, 2025):
Please note that it is now possible to offload AI tasks to a central service when hosting multiple PhotoPrism instances:
https://docs.photoprism.app/getting-started/config-options/#computer-vision
This should significantly reduce memory requirements.
You can do so by creating a "spare" instance, setting PHOTOPRISM_VISION_API to "true" in its configuration, and generating an API access token with the following command:
photoprism auth add --name=vision --scope=vision --expires=-1
Then, specify the access token as the key, along with the Vision API URL of the instance, in the configurations of the other instance, so it uses the service instead of the locally installed models, e.g.:
PHOTOPRISM_VISION_URI: "https://host.name/api/v1/vision"
PHOTOPRISM_VISION_KEY: "94b90f234fd0165290589e7bafeafa00a51d63deaeb9bj74"
@lastzero commented on GitHub (Jul 11, 2025):
Since you can also run pretty much all PhotoPrism CLI commands on other computers in the same network if shared storage has been configured and both computers can access the same database, I will move ahead and close this issue:
Implementing a custom network file system so that NFS, for example, is not required is out of scope. However, we might eventually support S3 storage for easier cloud hosting and scalability. There are already separate issues for that, e.g.: